MCP Tab¶
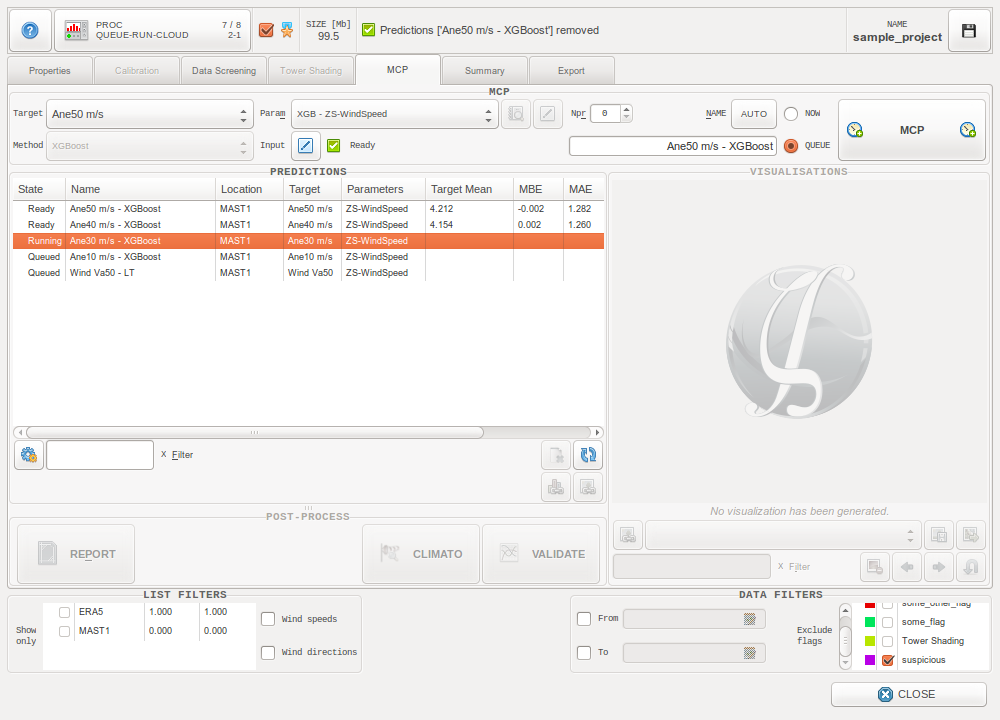
The MCP Tab
When performing a wind resource assessment, it is necessary to use local short-term wind measurements (typically one year) hand in hand with long-term meteorological data (typically 30 years) in order to account for both local specificities, and long-term variations in climatology.
To combine these two datasets into one local long-term climatology, one needs to use a “Measure Correlate Predict” method (MCP). This process will correlate the local short-term data with the long-term data from a reference point, in order to then extrapolate the short-term data onto the long-term period at the site of interest.
With the fast development of the Artificial Intelligence (AI) field in recent years, it has also become possible to use machine learning technologies to perform MCP. To this end, Zephy-Science has developed a MCP process based on the XGBoost machine learning algorithm.
To assess the accuracy of the predictions, the process has a built-in cross-validation step which builds several MCP models using different subparts of the source set, and validates each of them against the unused short-term data. Of course the final model is built using all the available short-term data.
The predicted data resulting from a MCP process is added to the ZephyWDP project as a new data serie. MCP processes are logged in the main treeview of the Tab, and accuracy indicators (MBE, MAE, RMSE) can be found there.
Process options¶

Select a data series to use as the target short-term data.

Select the MCP method to use. As of version 19.12, only the XGBoost method is available.

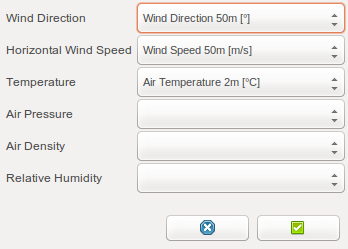
Select the data series to be input as long-term reference data.
Series of wind directions, wind speeds, temperatures, air pressures, air densities and relative humidities can be taken as input reference data.
The more data series are given as input, the more precise the model becomes. However, a larger input dataset will also incur longer computation times.
Process Parameters¶
The parameters defining the MCP process are read from the selected set of parameters. User’s default set of parameters is automatically selected in the list.
There are 2 predefined sets of parameters to perform XGBoost MCP:
- ZS-WindSpeed
- ZS-Temperature
ZS-Temperature is notably faster than ZS-WindSpeed.
“ZS-WindSpeed” is meant for predicting wind speeds. It will perform an automatic optimization of the XGBoost estimator by sampling 10 possible sets of parameters. There will be between 130 and 230 trees to fit, with a maximum tree depth between 9 and 12.
When using this set of parameters, it is mandatory to have a series of wind directions and a series of wind speeds in the input reference data. It is also recommended to input series of temperatures, air pressures and air densities when there are some available.
“ZS-Temperature” is meant for predicting temperatures. It will perform an automatic optimization of the XGBoost estimator by sampling 5 possible sets of parameters. There will be between 100 and 150 trees to fit, with a maximum tree depth of either 3 or 4.
When using this set of parameters, it is mandatory to have a series of wind directions and a series of temperatures in the input reference data. It is also recommended to input a serie of wind speeds when there is one available.

It is always possible to customize these sets of parameters with user defined settings:
XGBoost settings¶
The XGBoost model can be built either by using predefined parameters, or by performing an automatic parameter optimization by cross-validated search over parameter settings.

Performing a parameter optimizations is significantly longer than just using predefined parameters.
max_depth¶
Maximum tree depth for base learners.
Increasing this value will make the model more complex and more likely to overfit. Beware that XGBoost aggressively consumes memory when training a deep tree.
Conditions
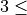 max_depth
max_depth 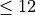
eta¶
Boosting learning rate.
Step size shrinkage used in update to prevents overfitting. After each boosting step, we can directly get the weights of new features, and eta shrinks the feature weights to make the boosting process more conservative.
Conditions
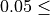 eta
eta 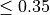
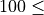 n_estimators
n_estimators 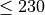
gamma¶
Minimum loss reduction.
Minimum loss reduction required to make a further partition on a leaf node of the tree. The larger gamma is, the more conservative the algorithm will be.
Conditions
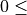 gamma
gamma 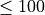
min_child_weight¶
Minimum weight needed in a child.
If the tree partition step results in a leaf node with the sum of instance weight less than min_child_weight, then the building process will give up further partitioning. The larger min_child_weight is, the more conservative the algorithm will be.
Conditions
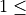 min_child_weight
min_child_weight
subsample¶
Subsample ratio of the training instance.
Setting it to 0.5 means that XGBoost would randomly sample half of the training data prior to growing trees. This will prevent overfitting. Subsampling will occur once in every boosting iteration.
Conditions
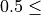 subsample
subsample 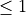
colsample_bytree¶
Subsample ratio of columns.
Specifies the fraction of columns to be subsampled when constructing each tree. Subsampling occurs once for every tree constructed.
Conditions
- colsample_bytree
lambda¶
L2 regularization term on weights
Increasing this value will make the model more conservative.
Conditions
- lambda
n_iter¶
Number of samplings
Only for parameter optimization: Number of parameter settings that are sampled. n_iter trades off runtime vs quality of the solution.
Conditions
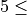 n_iter
n_iter 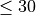
n_split¶
Number of cross-validation folds
Only for parameter optimization: The number of folds in the K-fold cross-validation used for optimization.
Conditions
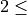 n_split
n_split 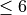
Validation parameters¶
The XGBoost model can be validated either by a repeated K-fold cross-validation, or by an alternating n-hour slices cross-validation.

A repeated K-fold cross-validation will perform several K-fold cross-validations one after the other. For each cross-validation, the data is split up in random folds of equal size. The repetitiveness of this operation make up for the randomness of the splits. The final results are very reliable.
An alternating n-hour slices cross-validation will split the data in slices with a fixed length. These slices are then considered as an alternation of training data and test data, meaning that one out of every two slice is used as training data. Consequently only two different validations can be performed that way.
Performing a repeated K-fold cross-validation is significantly longer than using an alternating n-hour slices cross-validation. However, the repeated K-fold has the advantage of reducing the uncertainty on the validation results.
注解
In a case where no validation is selected but the model is built using a parameter optimization, validation results will still be available as they will be taken directly from the parameter optimization step. However, these will be less reliable than validation results obtained through a repeated K-fold cross-validation.
kfold_nsplit¶
Number of cross-validation folds
Only for repeated K-fold cross-validation: The number of folds in every cross-validation.
Conditions
- kfold_nsplit
kfold_nrepeat¶
Number of repeated cross-validations
Only for repeated K-fold cross-validation: The number of different cross-validations to perform.
Conditions
- kfold_nrepeat
alter_nhour¶
Length of slices in hour
Only for alternating n-hour slices cross-validation: The length of each slice of data, in hour.
Conditions
- alter_nhour
Visualizations¶
As of version 19.12, the visualization module for MCP results has not been implemented yet. However, the predicted data can be processed and visualized in ZephyWDP as any other data serie.
XGBoost¶
What is XGBoost
XGBoost is an algorithm that has recently gained a lot of popularity due to its huge success in machine learning competitions (e.g. Kaggle competitions, where the main focus is on prediction problems). It is an implementation of gradient boosted decision trees designed for speed and performance. It stands for eXtreme Gradient Boosting.
At the lowest level, this method is based on decision trees. Such a tree is a sequence of simple classification decisions based on range tests on the predictor data (in our case, the long-term data). It leads ultimately to a subclass (called a node, or “leaf”) where the value we want to predict is considered to be a known constant, and this known value is therefore taken as a prediction.
A tree is built by splitting the source set (short-term data + corresponding values from the long-term data), into subsets. The splitting is based on a set of defined splitting rules. This process is repeated on each derived subset in a recursive manner. The recursion is completed when the subset at a node has constant values of the target variables, or when splitting no longer adds value to the predictions.
To use such inexpensive but inaccurate models and make them into a highly accurate model, a method called “boosting” is needed. Put simply, boosting is a method of converting weak learners into strong learners. It will recursively build new trees while increasing the weights of the observations in the source set which were hard to classify. The final model becomes a combination of all the trees which were built, its predictions being a weighted sum of the tree predictions. In the case of Gradient Boosting, many tree models are trained in a gradual, additive and sequential manner.
Application to wind
The crucial point when applying XGBoost to MCP in the wind industry, is to carefully choose the model parameters and which wind characteristics should be used as inputs.
Thus the development of this tool mainly consisted in calibrating the algorithm, through tests. Depending on which wind charasteristic is being predicted, this calibration can vary widely.